Parts of a Software Experiment September 7th, 2018
Software Experimentation, also often called A/B Testing, is a great methodology to guide decision-making. In this post I will attempt to break down all of the essential parts from a high-level, while trying not to get too deep into the weeds.
Hypothesis
The hypothesis clearly states a measureable goal, and how you intend to reach it.
Example hypothesis: Allowing free trials created in the month of October to have access to a premium feature that they otherwise would not have will increase conversion rate by 10%.
When you are creating your hypothesis, it is important to measure something that truly matters (big surprise: it should usually be money).
User Bucketing
In your application, you'll need a way to determine whether the user qualifies to be considered part of the experiment audience, and if so, which variation they should experience (including returning visits).
For our example, a simple requirement for the audience might be that the user created a free trial in the month of October.
When a user satisfies the audience requirement, you will then need to split those users into "buckets", or variations. For a simple A/B Test, you would split those users into a Control bucket and a Treatment bucket. Users who do not satisfy the audience requirement are not considerd a part of the experiment.
Users in the Control bucket do not experience any experimental changes, where as users in the Treatment bucket will experience the experimental changes. For our example, the users in the Treatment bucket will get access to a premium feature for their free trial period.
The technology behind user bucketing could be either custom code that you write, or you could use one of the many paid experimentation or feature-flag services that exist such as Optimizely or Launch Darkly .
Event Tracking
In order to measure the success of an experiment, you'll need an event tracking system. Track calls should be fired at key milestones, and include the necessary data to allow us to group by experiment variation when reporting.
# example track call
{
accountId: 4584,
action: 'Conversion to Paid Plan',
experiment: 'Trial + Premium Feature',
variation: 'treatment',
}
Analysis
Once the duration of the experiment has completed, we should be able to report on the data that was collected by our event tracking strategy. Ideally the data is a system where we can aggregate our tracking events by experiment, action, and variation like this:
| Experiment | Action | Control | Treatment |
|---|---|---|---|
| Trial + Premium Feature | Created Account | 2010 | 2003 |
| Trial + Premium Feature | Conversion to Paid Plan | 213 | 237 |
Okay, so we do see an increase in Treatment Conversions, but is it statistically significant? We need to run these numbers through a Bayesian Calculator to get a better idea. Luckily, that is very easy to do since there are multiple websites offering this calculation, such as AB Testguide's Bayesian A/B-test Calculator.
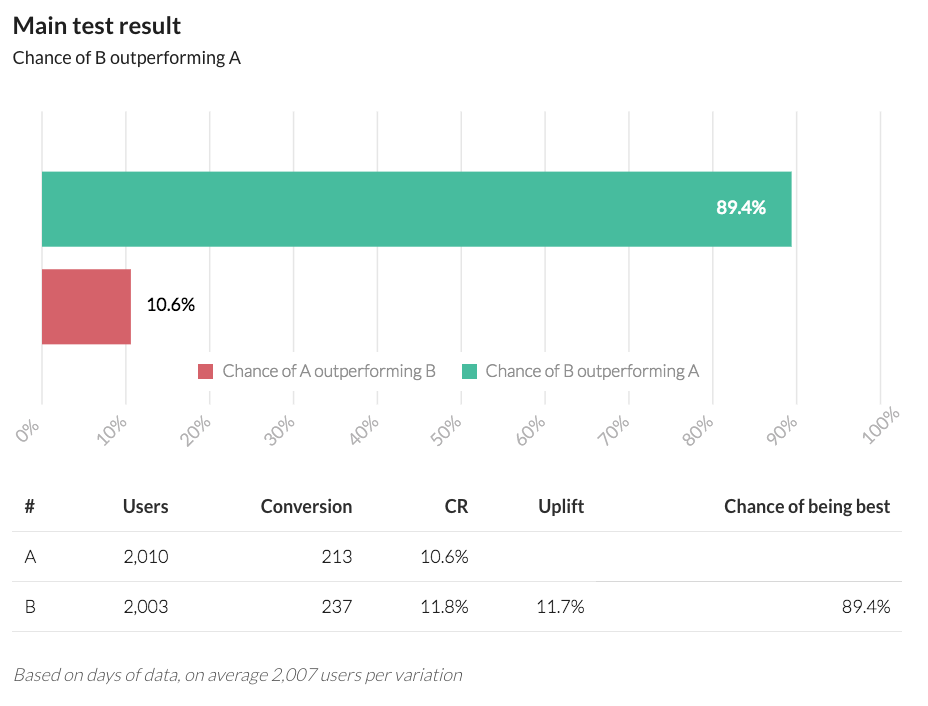
The screenshot above shows the result of plugging our conversion numbers into the Bayesian Calculator. The simulation suggests that there is an 89% probability that our Treatment out-performs our Control. Is 89% good enough? That is still an open question. My suggestion would be for your team to adopt a success criteria such as 85% or 90% and stick to that rule for everything you test. If it were my business, I think 89% probability would be a strong enough indication to adopt the Treatment variation as the new standard.
In Conclusion
The essential parts of a Sofware Experiment are: Hypothesis, User Bucketing, Event Tracking, and Analysis. Using the experimentation methology is a very powerful way to adopt data-driven decision-making on your team. Hopefully this post will help somebody better understand why they'd want to use Software Experimentation, or what their next steps might be to get started.